
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- 전처리
- seaborn
- 그로스해킹
- PostgreSQL
- 데이터시각화
- 데이터리안 웨비나
- 결측값
- 파이썬
- 머신러닝
- having
- Oracle
- MySQL
- pandas
- not in
- join
- GROUPBY
- solvesql
- SQL
- SQLite
- 다중 JOIN
- Limit
- Round
- SUM
- airflow.cfg
- hackerrank
- airflow 설치
- matplotlib
- TRUNCATE
- 데이터분석
- 프로그래머스
- Today
- Total
Milky's note
[Pandas] 데이터프레임 groupby로 연산된 컬럼 추가 (transform) 본문
요즘에 지하철 데이터를 가지고 토이 프로젝트를 진행해보려고 서울시에서 제공하는 오픈 API를 써서 데이터를 수집하고 있다. daily로 역, 호선 별 지하철 승하차 인구 데이터를 불러왔는데 이 데이터를 일간 말고 월간으로 인구를 sum을 해서 dataframe에 컬럼을 추가해주고 싶었다.
그럴 때 groupby와 transform 함수를 사용해주면 아주아주 편리하게 추가할 수 있다.
먼저 API를 통해서 데이터를 호출하고 아주 약간의 클렌징을 한 데이터이다.
데이터를 보면 USE_DT라는 컬럼이 daily로 수집되고 있다.

이 데이터를 groupby를 해서 month 기준으로 sum한 컬럼을 추가하려고 한다.
먼저 그냥 groupby를 해서 sum을 구해보면 아래와 같은 형태로 나온다.
날짜(연도월), 지하철 호선, 역이름으로 groupby를 하였다.
# YYYYmm까지만 나오게 하기 위해 전처리 코드 추가
df['USE_MON'] = df['USE_DT'].astype('str').str.replace('-','')
df['USE_MON'] = df['USE_MON'].str[0:6]
df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM']).sum()
groupby된 데이터 중 합계 컬럼을 다시 기존 데이터프레임에 join을 하려면 key를 찾고 merge나 join 함수를 써서 컬럼을 추가해주어야 하기 때문에 코드가 늘어난다.
바로 이럴 때 transform 함수를 사용하면 groupby한 데이터를 데이터프레임의 컬럼에 추가할 수 있다.
사용 방법은 아래와 같다.
# YYYYmm까지만 나오게 하기 위해 전처리 코드 추가
df['USE_MON'] = df['USE_DT'].astype('str').str.replace('-','')
df['USE_MON'] = df['USE_MON'].str[0:6]
df['RIDE_SUM'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['RIDE_PASGR_NUM'].transform('sum')
df['ALIGHT_SUM'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['ALIGHT_PASGR_NUM'].transform('sum')
df
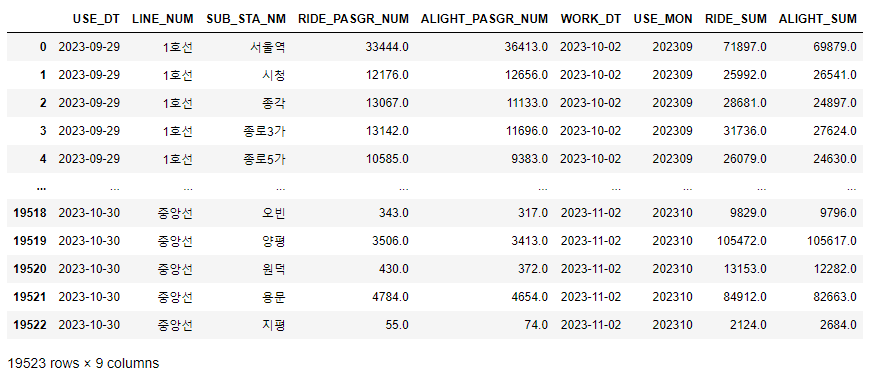
transform 함수는 sum 뿐만 아니라 groupby에 사용하는 연산함수에 대해서 다 적용이 가능하다.
- count 예시
#위에서 추가한 sum 컬럼 삭제
df = df.drop(columns = df.columns[[-2,-1]])
df['RIDE_CNT'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['RIDE_PASGR_NUM'].transform('count')
df['ALIGHT_CNT'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['ALIGHT_PASGR_NUM'].transform('count')
df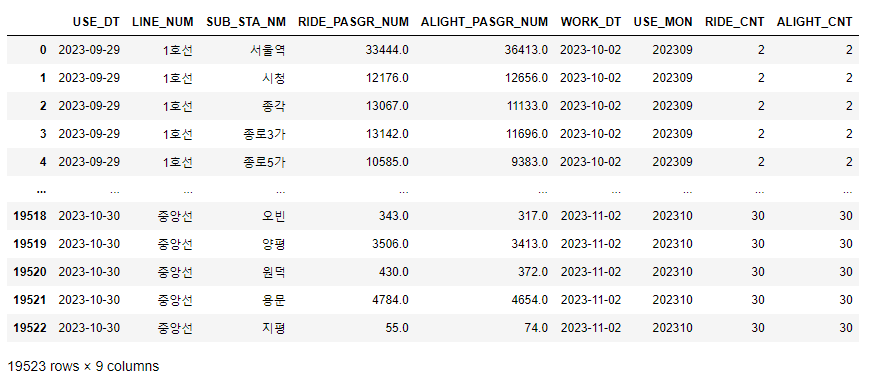
- min, max 예시
df = df.drop(columns = df.columns[[-2,-1]])
df['RIDE_MIN'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['RIDE_PASGR_NUM'].transform('min')
df['ALIGHT_MAX'] = df.groupby(['USE_MON', 'LINE_NUM', 'SUB_STA_NM'])['ALIGHT_PASGR_NUM'].transform('max')
df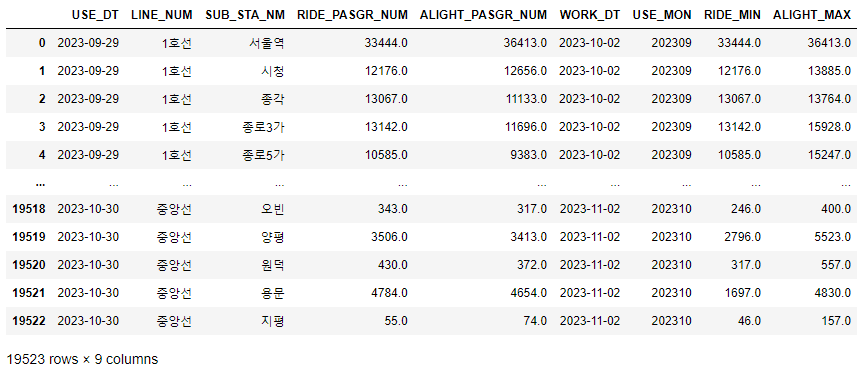
transform 함수를 사용해서 편하게 groupby 연산한 데이터를 컬럼에 바로 추가할 수 있당 !!!!
'Python > 요약 정리' 카테고리의 다른 글
| [Pandas] 데이터프레임 컬럼 SHA256으로 암호화하기 (0) | 2024.01.08 |
|---|---|
| [Pandas] 데이터프레임 컬럼 순서 변경 (1) | 2023.11.13 |
| [Python] timedelta(months=n) (2) | 2023.11.13 |
| [K-Digital] 자주쓰이는 pandas 정리 (0) | 2022.05.24 |
| [K-Digital] Seaborn (0) | 2022.05.18 |


