
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- 전처리
- having
- solvesql
- airflow.cfg
- SQLite
- Limit
- 프로그래머스
- 데이터리안 웨비나
- pandas
- 데이터시각화
- Round
- 파이썬
- TRUNCATE
- matplotlib
- not in
- 데이터분석
- hackerrank
- 그로스해킹
- join
- 머신러닝
- MySQL
- Oracle
- 다중 JOIN
- 결측값
- GROUPBY
- airflow 설치
- SUM
- PostgreSQL
- SQL
- seaborn
Archives
- Today
- Total
Milky's note
[PostgreSQL] Window Function 본문
데이터 분석 코딩테스트에서 판다스와 WINDOW_FUNCTION 중에서,
대부분이 SQL WINDOW_FUNCTION의 비중이 크다고 하였다.
사실은 블로그가 너무너무 써보고 싶어서 오늘 공부하고 빠르게 업로드한당^_^
아직 개념만 잡은 단계라 실제 로그 분석 할 때 많이 쓰면서 익혀야겠다
1. 개념
- 행과 행 간의 관계를 쉽게 정의하기 위해 만든 함수가 윈도우함수이다.
- 순위, 합계, 평균, 행 위치 등을 조작할 수 있다.
- 분석 함수나 순위 함수로도 알려져 있다.
- 다른 함수와 달리 중첩해서 사용은 못하지만, 서브쿼리에는 사용이 가능하다.
(물론 PostgreSQL만 지원하는 기능이 아니고, 대다수의 DBMS에서도 사용 가능하다.) - CF>> Aggregate Function
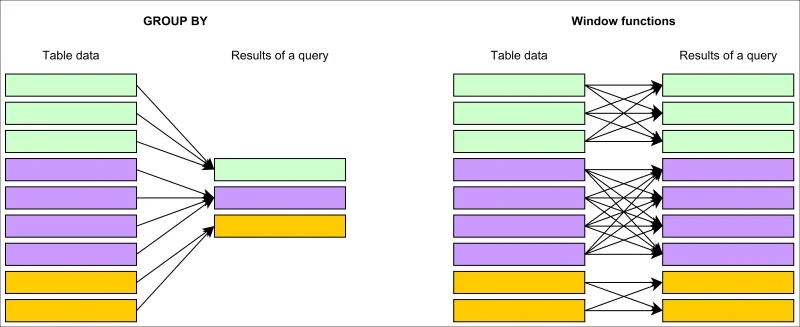
Window 함수는 Aggregate 함수처럼 계산을 도와주지만,
Aggregate 함수는 결과가 하나의 Row로 보여주고,
Window 함수는 Row마다 결과를 보여준다.
GROUP BY를 사용하지 않고도 SQL의 Aggregate 함수를 사용할 수 있다.
(즉, GROUP BY 구문과 병행하여 사용할 수 없다.)
2. 구조
- Aggregate 함수로 Window 함수를 사용하려면 Aggregate 함수 뒤에, OVER을 붙이고 Window 함수로 지정한다.
(만약 OVER를 지정하지 않으면 테이블 전체에 Aggregate 함수가 적용됨) - PARTITION BY (컬럼)을 지정하면 해당 컬럼 값을 기반으로 그룹화하고 Aggregate 함수가 적용된다.
(말로 풀이하는게 제일 어렵당.. 그냥 SQL 보면 더 이해가 빠르다. 결론 : OVER 꼭 쓰기!!!!!!!!!!!!!!!!!!!!!!!!!!!!)
SELECT WINDOW_FUNCTION (ARGUMENTS) OVER
( [PARTITION BY 컬럼] [ORDER BY 컬럼] [WINDOWING 절] )
FROM 테이블명 ;- WINDOW_FUNCTION : 윈도우 함수
- ARGUMENTS(인수) : 함수에 따라 0 ~ N개 인수가 지정될 수 있다.
- PARTITION BY 절 : 전체 집합을 기준에 의해 소그룹으로 나눌 수 있다.
- ORDER BY 절 : 어떤 항목에 대해 순위를 지정할 지 order by 절을 기술한다.
- WINDOWING 절 : WINDOWING 절은 함수의 대상이 되는 행 기준의 범위를 강력하게 지정할 수 있다.
(sql server 에서는 지원하지 않음)
3. WINDOW_FUNCTION 사용가능 함수
윈도우 함수는 특정 항목과 파티션에 대해서 순위를 계산할 수 있는 함수를 제공한다.
[예제 테이블]
select * from sample;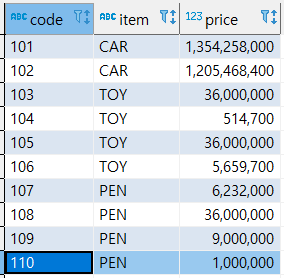
- 순위 함수(RANK Function)
- RANK()
특정항목 및 파티션에 대해서 순위를 계산한다.
동일한 순위는 동일한 값이 부여된다.
select code, item, price, rank() over (order by price desc) ALL_RANK, -- 전체 데이터 중에서의 RANK rank() over (partition by item order by price desc) ITEM_RANK -- item 별로 나눈 그룹에서의 RANK from sample;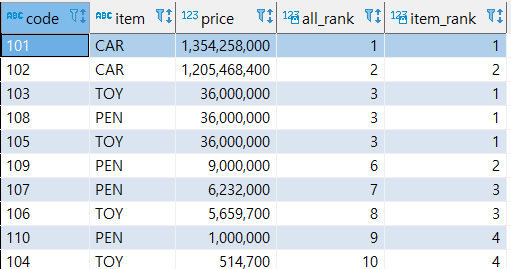
- DENSE_RANK()
동일한 순위를 하나의 건수로 계산한다.
select code, item, price, dense_rank() over (order by price desc) ALL_RANK, -- 전체 데이터 중에서의 RANK dense_rank() over (partition by item order by price desc) ITEM_RANK -- item 별로 나눈 그룹에서의 RANK from sample;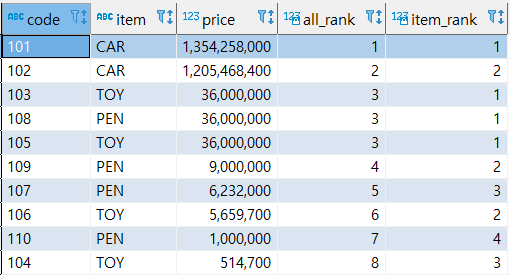
- ROW_NUMBER()
동일한 순위에 대해서 고유의 순위를 부여한다.
select code, item, price, rank() over (order by price desc) ALL_RANK, -- 전체 item에 대한 RANK(동일 순위) row_number() over (order by price desc) row_number -- 전체 item에 대한 RANK(고유 순위) from sample;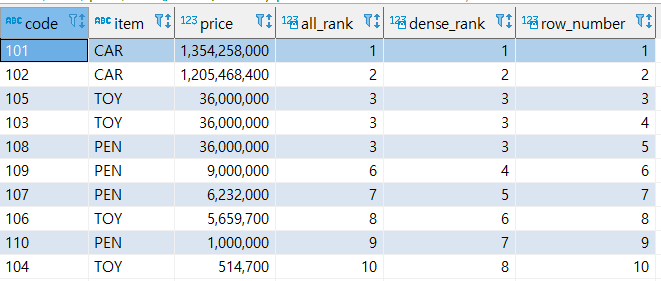
- 집계 함수(AGGREGATE Function)
- SUM(컬럼)
파티션 별로 합계를 계산한다.
select code, item, price, sum(price) over (partition by item) from sample;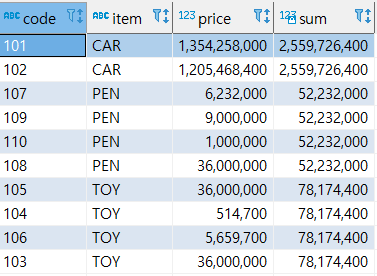
- AVG(컬럼)
파티션 별로 평균을 계산한다.
select code, item, price, avg(price) over (partition by item) from sample;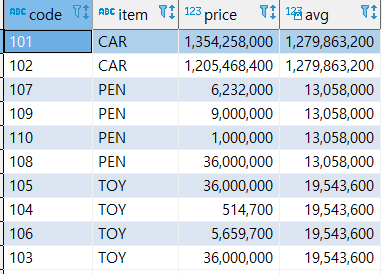
- COUNT(컬럼)
파티션 별로 행 수를 계산한다.
select code, item, price, count(price) over (partition by item) from sample;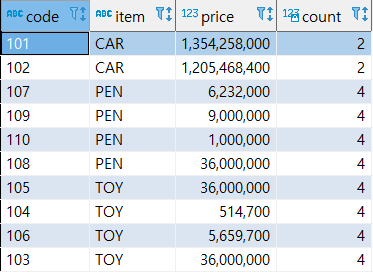
- MAX(컬럼)
파티션 별로 최댓값을 계산한다.
select code, item, price, max(price) over (partition by item) from sample;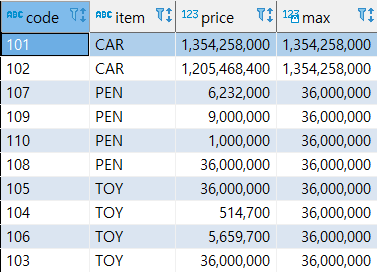
- MIN(컬럼)
파티션 별로 최솟값을 계산한다.
select code, item, price, min(price) over (partition by item) from sample;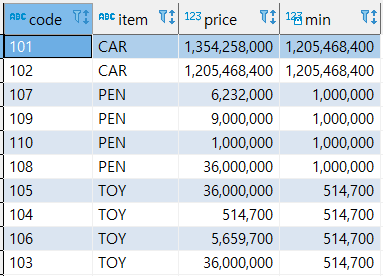
- 행 순서 관련 함수
행 순서 관련 함수는 상위 행 값을 하위에 출력하거나 하위 행 값을 상위 행에 출력할 수 있다.
특정 위치의 행을 출력할 수 있다.
- FIRST_VALUE(컬럼)
파티션에서 가장 처음에 나오는 값을 구한다.
MIN 함수를 사용해서 같은 결과를 구할 수 있다.
select code, item, price, first_value(code) over (partition by item order by price rows unbounded preceding) -- 있어도 없어도 똑같은 결과 from sample;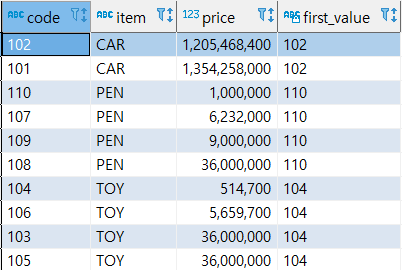
- LAST_VALUE(컬럼)
파티션에서 가장 나중에 나오는 값을 구한다.
MAX 함수를 사용해서 같은 결과를 구할 수 있다.
select code, item, price, last_value(code) over (partition by item order by price rows between unbounded preceding and unbounded following) -- 범위가 첫 번째부터 마지막 행까지 from sample; -- rows between current row and unbounded following) 범위가 현재 행부터 마지막 행까지 -- 위에 지정해준 범위와 출력 결과는 똑같이 나옴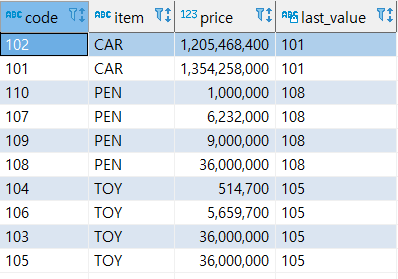
- LAG(컬럼, 행값, (결측 값 일 때, 채울 값))
이전 행을 가지고 온다.
기본값은 1이다.
select code, item, price, lag(price, 2) over (order by item -- price 컬럼의 2칸 이전의 값 rows between current row and unbounded following) -- 범위는 행의 처음부터 끝까지 from sample; -- lag(price, 2, 0) 맨 마지막 파라미터는 값이 null일 경우 채워 넣을 값을 지정할 수 있음
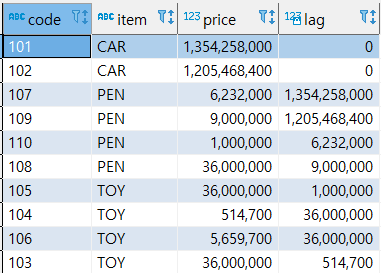
- LEAD(컬럼, 행값, (결측 값 일 때, 채울 값))
이후 행을 가지고 온다.
기본값은 1이다.
select code, item, price, lead(price, 3) over (order by item -- price 컬럼의 3칸 이후의 값 rows between current row and unbounded following) -- 범위는 행의 처음부터 끝까지 from sample; -- lead(price, 3, 0) 맨 마지막 파라미터는 값이 null일 경우 채워 넣을 값을 지정할 수 있음
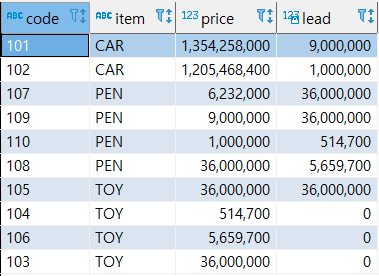
- 비율 관련 함수
비율 관련 함수는 누적 백분율, 순서별 백분율, 파티션을 N분으로 분할한 결과 등을 조회할 수 있다.
- CUME_DIST()
파티션 전체 건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 조회한다.
누적 분포상에 위치를 0~1사이의 값을 가진다.
select code, item, price, cume_dist() over (partition by item order by price) from sample;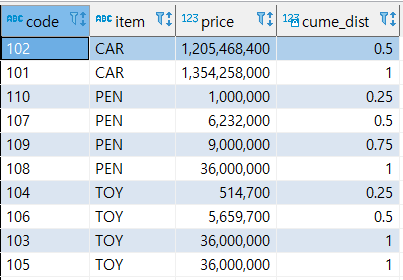
- PERCENT_RANK()
파티션에서 제일 먼저 나온 것을 0으로 제일 늦게 나온 것을 1로 하여 값이 아닌 행의 순서별 백분율을 조회한다.
select code, item, price, percent_rank() over (partition by item order by price) from sample;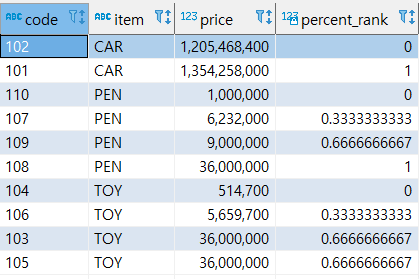
- NTILE(N)
파티션 별로 전체 건수를 ARGUMENT 값으로 N등분한 결과를 조회한다.
select code, item, price, ntile(3) over (partition by item order by price desc) -- 총 10건의 컬럼을 3으로 등분 from sample;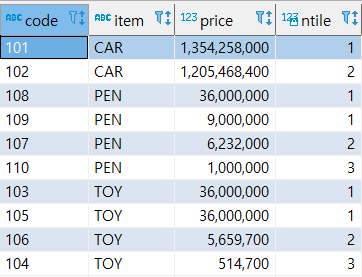
- RATIO_TO_REPORT(컬럼)
파티션 내에 전체 SUM(컬럼)에 대한 행 별 컬럼 값의 백분율을 소수점까지 조회한다.
PostgreSQL에서는 다음 함수가 없어서 해당 수식을 만들어서 사용한다.
SELECT code, item, price, 1.0 * price / NULLIF(SUM(price) OVER(PARTITION BY item),0) AS ratio_to_report -- 컬럼 값의 합에 대한 컬럼의 비율을 계산 FROM sample; -- 오라클 같은 경우에는 다음과 같이 쓴다 select code, item, price, ratio_to_report(price) over (partition by item order by price desc) from sample;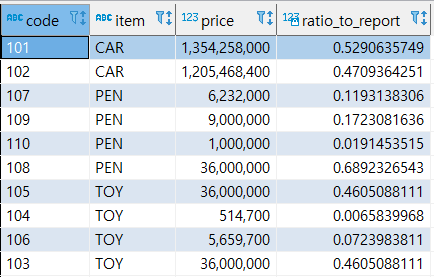
4. WINDOWING 절
- ROWS
부분집합인 윈도우 크기를 물리적 단위로 행의 집합을 지정한다. - RANGE
논리적 주소에 의해 행 집합을 지정한다. - BETWEEN~AND
윈도우의 시작과 끝 위치를 지정한다. - UNBOUNDED PRECEDING
윈도우 시작 위치가 첫 번째 행임을 의미한다. - UNBOUNDED FOLLOWING
윈도우 마지막 위치가 마지막 행임을 의미한다. - CURRENT ROW
윈도우 시작 위치가 현재 행임을 의미한다.
(데이터가 인출된 현재 행을 의미한다.)각 함수에 대한 예시와 전체적인 SQL에 대한 예시는 추후 작성해야겠당
'SQL > 요약 정리' 카테고리의 다른 글
| [K-Digital] 데이터 모델링 (0) | 2022.05.18 |
|---|---|
| [PostgreSQL] Table Partitioning (0) | 2022.01.06 |
| [PostgreSQL] Vacuum 수행 (2) | 2022.01.05 |
'SQL/요약 정리' Related Articles
more



Comments