
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
Tags
- seaborn
- hackerrank
- not in
- 파이썬
- matplotlib
- SQLite
- 데이터분석
- Round
- GROUPBY
- solvesql
- PostgreSQL
- SUM
- MySQL
- 데이터리안 웨비나
- 그로스해킹
- 결측값
- airflow 설치
- TRUNCATE
- 전처리
- 머신러닝
- Limit
- 데이터시각화
- 다중 JOIN
- join
- having
- 프로그래머스
- SQL
- Oracle
- airflow.cfg
- pandas
Archives
- Today
- Total
Milky's note
가상 쇼핑몰 고객 주문데이터 2. 고객 Retention 코호트 분석 본문
먼저 코호트 분석을 하기 전에 코호트란 ?
간단하게 말하면 같은 기간동안 같은 경험을 한 집단을 나타낸다.
코호트 분석은 그로스해킹 카테고리에 자세한 설명을 써야두어야겠다.
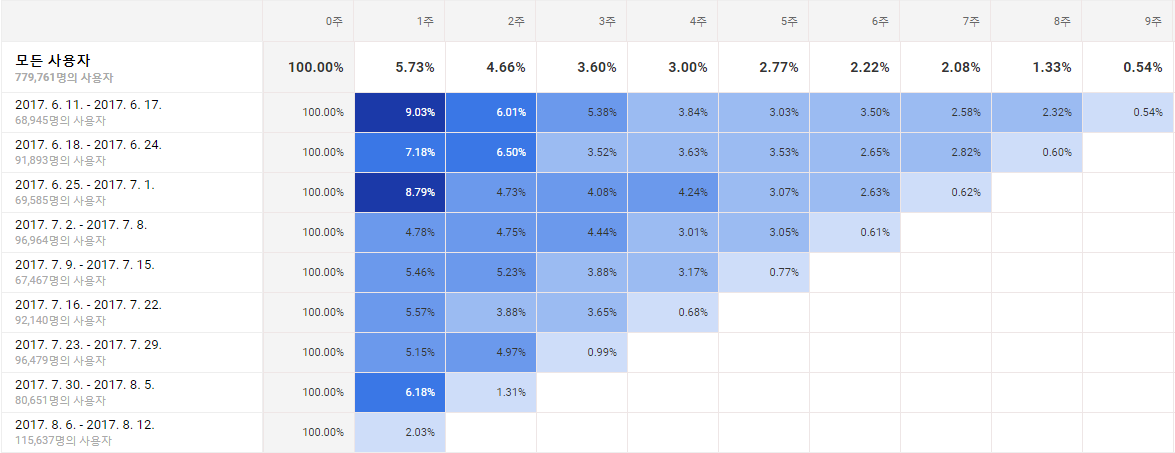
사용자 retention 분석
- 월간 사용자 cohort를 바탕으로 월별 재구매율(retention) 분석하기
- heatmap으로 한눈에 재구매율을 파악 가능
이제 본격적으로 코호트 분석을 할 예정이다.
이전에 데이터 전처리한 데이터를 불러온다.
먼저 코호트 예시에 있는 왼쪽 기간부터 구해주어야한다.
사용자 기준으로 최초 구매한 월(month) 연산하기
- Month : 구매월(일(day)을 무시)
- MonthStarted: 사용자가 최초 구매한 달
- 코호트 차트의 왼쪽 기준이 되는 시간을 구하기 위함
# 뒤의 날짜는 무시하고 년도와 월만 뽑아내게 함수 생성
# 일은 1로 고정시킨다.
def get_month(date):
return datetime(date.year, date.month,1)
retail['Month']=retail['InvoiceDate'].apply(get_month)
month_group=retail.groupby('CustomerID')['Month']
# MonthStarted 컬럼을 생성하여 해당 고객이 구매한 가장 빠른 달을 구해줌
retail['MonthStarted']=month_group.transform(np.min)
retail.head()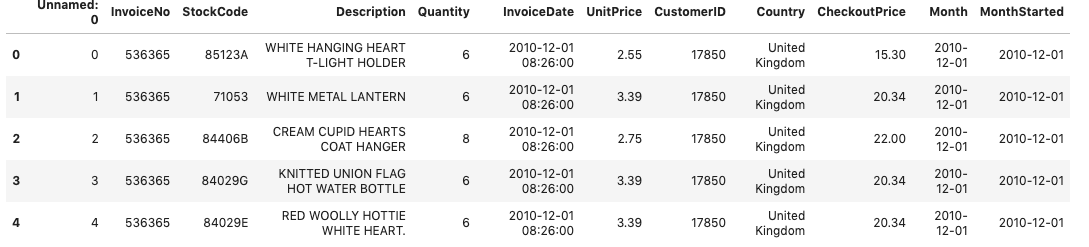
기준이 되는 월과 실제 구매 월의 차이 계산하기
- 각 구매가 최초 구매로 부터 얼마의 월이 지났는지 연산
- MonthPassed : 최초 구매월로부터의 월 차이
- 코호트에서 위쪽 기간이 지난 부분을 나타내기 위함
retail['MonthPassed']=(retail['Month'].dt.year - retail['MonthStarted'].dt.year)*12 + \
(retail['Month'].dt.month - retail['MonthStarted'].dt.month)
# (해당 구매 년도 - 첫 구매 년도)*12 + (해당 구매 달 - 첫 구매 달)을 해주어서
# 해당 구매가 첫 구매일로부터 얼마나 지났는지 계산해주는 식
retail.tail()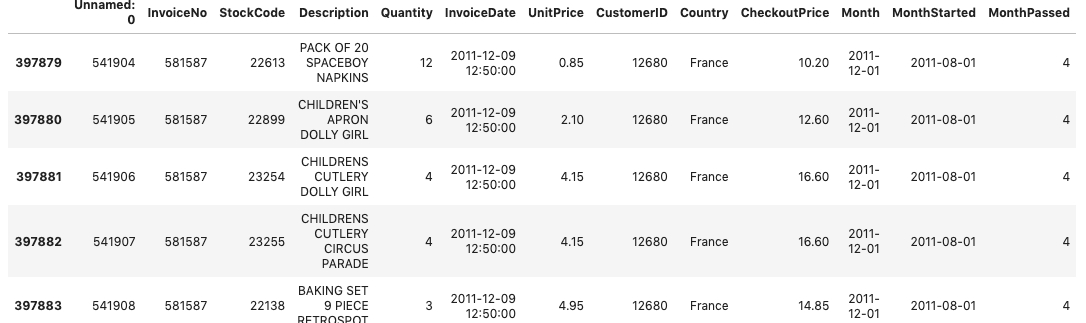
기준 월, MonthPassed를 기준으로 고객 카운팅
- 기준이 되는 월과 그 월로부터 지난 기간의 고객 수를 계산
- 코호트 기준 안 쪽 수치를 계산하기 위함
def get_unique(x):
return len(np.unique(x))
# 해당 기간 동안 고객이 여러 번 사는 경우도 있어서 이를 제외하기 위해 unique 함수를 사용하여
# 고객 1명이 얼마나 구매하는 지 계산
cohort = retail.groupby(['MonthStarted', 'MonthPassed'])['CustomerID'].apply(get_unique)
cohort = reset_index()
cohort.head()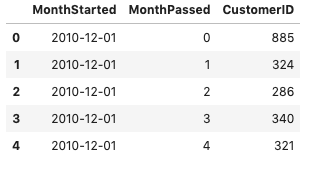
피벗 테이블 생성
- pivot 함수를 이용하여 index는 MonthStarted, columns을 MonthPassed로 변경하여 테이블 변경
- 첫번째 column을 기준으로 100분위 연산
- pivot 테이블을 이용하여 최종 코호트 차트로 나타내기 위함
cohort=pd.pivot_table(cohort,'CustomerID','MonthStarted','MonthPassed')
cohort.head()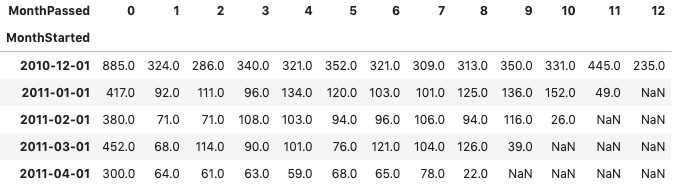
오...!! 피벗 테이블로 나타내니까 코호트 차트와 굉장히 유사한 데이터 프레임이 생성되었다. !!!
하지만 해당 값의 count가 아닌 비율로 나타내주어야해서 첫번째 컬럼 기준으로 100분위 연산을 한다.
cus_cohort=cohort.div(cohort.iloc[:,0], axis=0)*100
cus_cohort=round(cus_cohort,2)
cus_cohort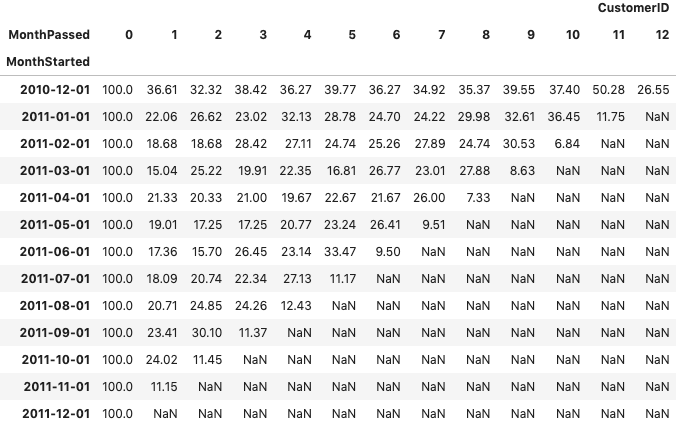
비율로 차트를 구해주었다 !!
이제 이를 보기 편하게 히트맵을 이용하여 시각화한다.
heatmap 출력하기
- seaborn의 heatmap 함수로 시각화
xticks = np.arange(0, 13)
yticks = ['2010/12', '2011/01', '2011/02', '2011/03', '2011/04', '2011/05', '2011/06', '2011/07', '2011/08', '2011/09', '2011/10', '2011/11', '2011/12']
plt.figure(figsize = (15, 8))
sns.heatmap(cus_cohort,
annot=True,
xticklabels=xticks,
yticklabels=yticks,
fmt='.1f',
cmap = 'Blues'
)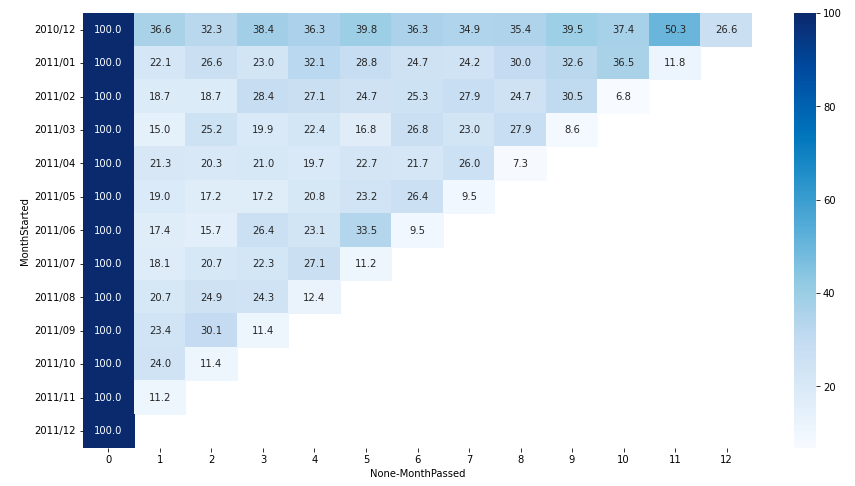
히트맵을 이용하여 코호트 분석을 하였다.
고객들의 재구매율을 나타내었는데 기간이 지날수록 재구매율이 낮아지고 있다.
이 자료를 제공하면 의사 결정에 도움을 줄 수 있길 바란다!
자세한 소스는 git에 업로드하였다.
GitHub - busyppp/Study
Contribute to busyppp/Study development by creating an account on GitHub.
github.com
'데이터 분석 > 데이터분석 연습' 카테고리의 다른 글
| 가상 쇼핑몰 고객 주문데이터 3. 고객 이탈률 퍼널 분석 (1) | 2022.05.28 |
|---|---|
| 가상 쇼핑몰 고객 주문데이터 1. 데이터 전처리 (0) | 2022.05.28 |
| 카페 상권 분석 (2) | 2022.05.26 |
| 전국 주차장 데이터 (0) | 2022.05.25 |
| 부동산 데이터 전처리 (0) | 2022.01.11 |
'데이터 분석/데이터분석 연습' Related Articles
more




Comments