
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- seaborn
- PostgreSQL
- not in
- 프로그래머스
- Round
- 머신러닝
- 데이터분석
- airflow.cfg
- SQL
- 결측값
- 전처리
- Limit
- having
- 파이썬
- airflow 설치
- 그로스해킹
- join
- MySQL
- 다중 JOIN
- pandas
- 데이터시각화
- matplotlib
- solvesql
- 데이터리안 웨비나
- hackerrank
- TRUNCATE
- Oracle
- SQLite
- GROUPBY
- SUM
- Today
- Total
Milky's note
전국 주차장 데이터 본문
전국 주차장 데이터를 통하여 다음을 분석하려고 한다.
- 지역 별 주차장에 대한 분석
- seaborn을 통한 주차장 시각화
데이터는 공공데이터 포털에서 받았고 위도와 경도를 이용한 데이터 시각화를 하기 위해 주차장 데이터를 찾아서 데이터 분석을 진행하였다.
한국교통안전공단_전국공영주차장정보_20191224
주정차문화지킴이 시스템에 등록된 전국공영주차장정보(위경도, 주차장 유형, 주소 등)
www.data.go.kr
1. 전처리
# null 값 데이터 삭제
park = park.dropna()
park.info()없는 데이터를 삭제해주어서 모두 not null인 걸 확인하였다.
| <class 'pandas.core.frame.DataFrame'> Int64Index: 9626 entries, 0 to 12804 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 주차장명 9626 non-null object 1 위도 9626 non-null float64 2 경도 9626 non-null float64 3 주차장구분 9626 non-null object 4 주차장유형 9626 non-null object 5 주차장도로명주소 9626 non-null object 6 지역구분 9626 non-null object 7 시군구 9626 non-null object dtypes: float64(2), object(6) memory usage: 676.8+ KB |
다음으로는 주차장 구분 컬럼에서 공영 주차장이 다음 3가지로 데이터가 수집이 되어있는 걸 확인하였다.
# 전국의 공영 주차장만 뽑아낸다.
park_public = park[(park['주차장구분'].str.contains('공영')) | (park['주차장구분'].str.contains('공용'))]
print(set(park_public['주차장구분']))
park_public{'공영주차장', '공용', '공영'}
공영주차장, 공용 을 모두 공영으로 바꾸어준다.
park['주차장구분'] = park['주차장구분'].str.replace('공용', '공영')
park['주차장구분'] = park['주차장구분'].str.replace('공영주차장', '공영')
print(set(park['주차장구분'])){'공영', '민영'}
2. 분석 set 생성
- 지역 별 주차장 비율
- 서울시 구별 주차장 비율
- 지역 별 공영 주차장 비율
- 서울시 시각화 데이터 셋
- 전국 시각화 데이터 셋
시각화를 하기 위해 위의 데이터 셋을 구할 예정이다.
· 지역 별 주차장 비율
park_city = park.groupby('지역구분')['주차장명'].count()
park_city = park_city.reset_index()
park_city = park_city.set_index('지역구분').sort_values(by='주차장명', ascending=False)
park_city['비율'] = np.round(park_city['주차장명']/sum(park_city['주차장명'])*100,3)
park_city
· 서울시 구별 주차장 비율
# "서울"에 위치하고 있는 주차장만 뽑아낸다.
park_seoul = park[park["지역구분"].str.contains("서울특별시")]
park_seoul.index = range(len(park_seoul))
print(f'전국 주차장 수 : {len(park)}')
print(f'서울시 주차장 수 : {len(park_seoul)}')
print(f'서울시 주차장 비율 : {len(park_seoul)/len(park) *100:.3f}%')
# 서울시의 구별로 위치하고 있는 주차장만 뽑아낸다.
park_seoul_gu = park_seoul.groupby('시군구')['주차장명'].count()
park_seoul_gu = park_seoul_gu.reset_index()
park_seoul_gu = park_seoul_gu.set_index('시군구').sort_values(by='주차장명', ascending=False)
park_seoul_gu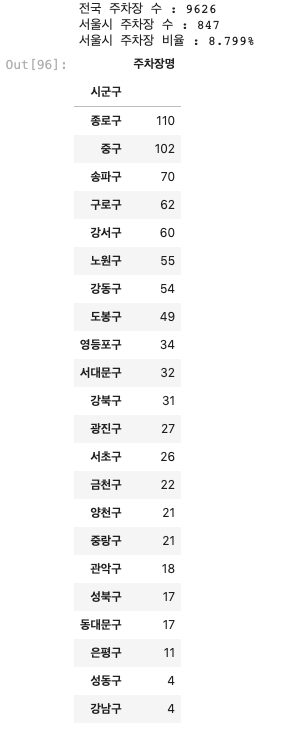
생각보다 서울시 주차장의 비율이 크지가 않았다.
그리고 강남구의 주차장이 4개로 서울시에서 제일 적은 결과가 나와서 뭔가 이상하다고 생각하고 주차장 구분을 확인해보았다.
그래서 민영 주차장이 서울시에 어떤 구에 있는 지 확인을 해보았다. 예상한대로 구가 별로 없었다.
공공데이터 포털에서 받아온 데이터인데 서울시 데이터가 조금 이상했다는 걸 확인했다.
이래서 전국의 비율도 내가 예상한 수치보다 적게 나왔다고 가정하기로 했다.
min = park[park['주차장구분'] == '민영']
min[min['지역구분'] == '서울특별시'].groupby(['지역구분','시군구'])['주차장명'].count()| 지역구분 시군구 서울특별시 강서구 16 금천구 10 도봉구 20 동대문구 1 양천구 2 종로구 71 중구 2 Name: 주차장명, dtype: int64 |
· 전국 공영 주차장 비율
park_public = park_public.groupby(['지역구분','시군구'])['주차장명'].count()
park_public = park_public.reset_index()
park_public = park_public.set_index('시군구').sort_values(by='주차장명', ascending=False)
park_public['비율'] = np.round(park_public['주차장명']/sum(park_public['주차장명'])*100,3)
park_public = park_public.head(10)
park_public전국이 너무 많아서 상위 10개로 제한을 했다.

3. 시각화
· 전국 주차장 비율
plt.figure(figsize=(15,4))
sns.barplot(data=park_city, x=park_city.index, y="주차장명")
plt.show()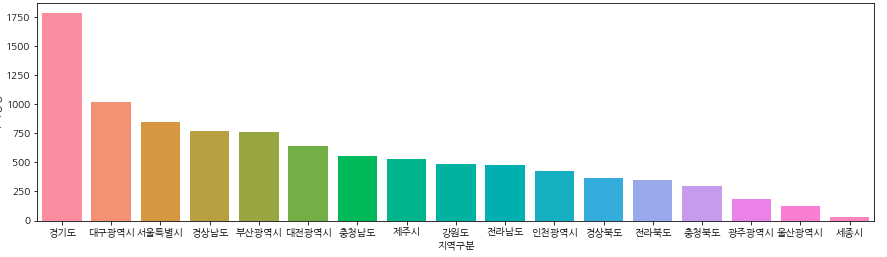
다음은 위의 바 그래프를 파이차트로 나타내어보자.
레이블의 갯수가 많아서 오히려 가독성을 해치기 때문에 상위 5개의 지역만 출력하게 해주었다.
경기도에 주차장이 제일 많다는 사실이 한 눈에 파악 가능하다.
labels = ['경기도', '대구광역시', '서울특별시', '경상남도', '부산광역시', '', '', '', '', '', '', '', '', '', '', '', '']
plt.figure(figsize=(10, 10))
plt.pie(park_city.비율,
labels= labels, #park_city.index,
autopct='%d%%',
startangle=95,
textprops={'fontsize':12}
)
plt.legend(park_city.index)
plt.show()
· 서울시 주차장 비율
plt.figure(figsize=(15,4))
sns.barplot(data=park_seoul_gu, x=park_seoul_gu.index, y="주차장명")
plt.show()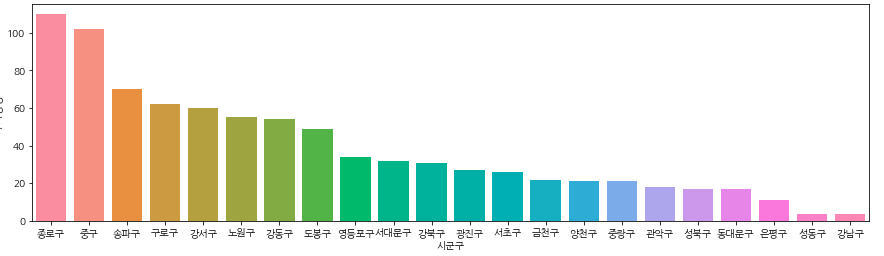
위의 바 그래프를 역시 파이차트로 그려볼 예정이다.
이 레이블들도 많아서 상위 5개만 출력되게 만들었다.
labels = ['종로구', '중구', '송파구', '구로구', '강서구', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '', '']
plt.figure(figsize=(13, 13))
plt.pie(park_seoul_gu.비율,
labels= labels, #park_city.index,
autopct='%d%%',
startangle=90,
textprops={'fontsize':12}
)
#plt.legend(park_seoul_gu.index)
plt.show()
· 전국 공영 주차장 비율
plt.figure(figsize=(15,4))
sns.barplot(data=park_public, x=park_public.index, y="주차장명")
plt.show()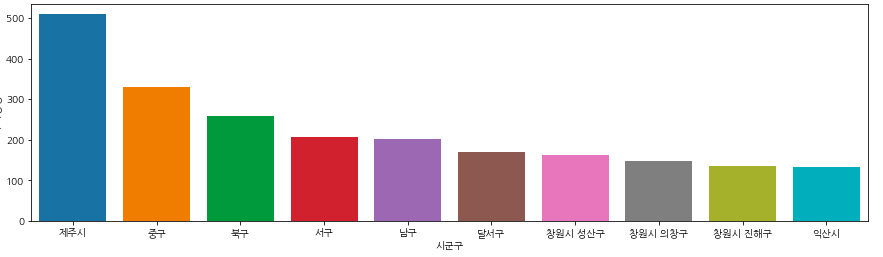
공영 주차장이 많은 지역의 파이차트 그래프이다.
레이블을 10개로 제한하여 깔끔하게 보이기 위해서 도너츠 모양의 파이차트를 그려보았다.
wedgeprops={'width': 0.7, 'edgecolor': 'w', 'linewidth': 5}
plt.figure(figsize=(13, 13))
plt.pie(park_public.비율,
labels= park_public.index,
autopct='%d%%',
startangle=90,
textprops={'fontsize':12},
wedgeprops=wedgeprops
)
#plt.legend(park_seoul_gu.index)
plt.show()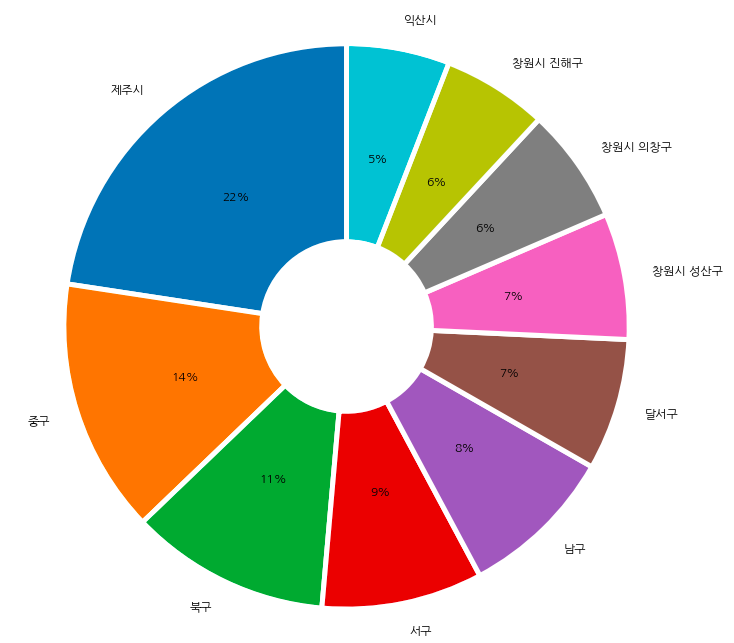
· 서울시 주차장 시각화(구별)
plt.figure(figsize=(10,8))
sns.scatterplot(data = park_seoul, x="경도", y="위도", hue="시군구")
· 서울시 주차장 시각화(주차장 구분별)
plt.figure(figsize=(10,8))
sns.scatterplot(data = park_seoul, x="경도", y="위도", hue="주차장구분")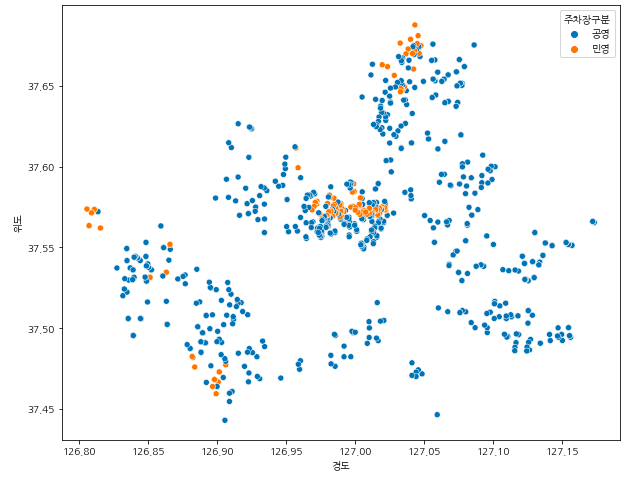
· 전국 주차장 시각화(구별)
plt.figure(figsize=(10,8))
sns.scatterplot(data = park, x="경도", y="위도", hue="지역구분")
plt.figure(figsize=(10,8))
sns.scatterplot(data = park, x="경도", y="위도", hue="주차장구분")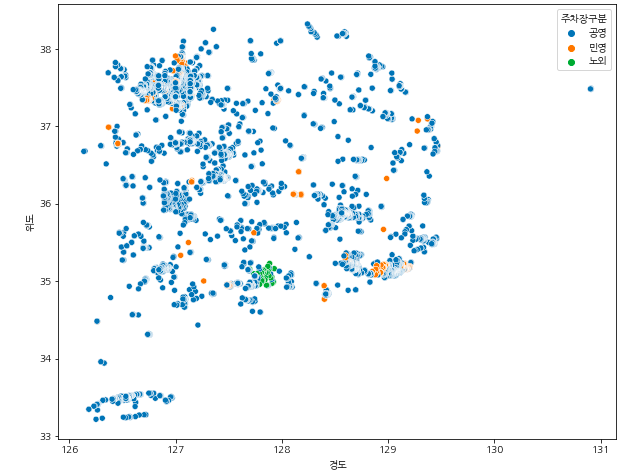
지역별, 주차장별로 데이터 시각화를 하였당 !!!
위도, 경도 데이터로 지도 시각화를 하고 싶어서 이 데이터를 선택하였는데 정말 재미있는 데이터분석이었다.
아쉬운 점은 서울시의 민영 주차장 데이터가 없어서 내 생각과는 다른 결과가 나왔다.
GitHub - busyppp/Study
Contribute to busyppp/Study development by creating an account on GitHub.
github.com
자세한 소스는 깃허브에 올려놓았다!
'데이터 분석 > 데이터분석 연습' 카테고리의 다른 글
| 가상 쇼핑몰 고객 주문데이터 3. 고객 이탈률 퍼널 분석 (1) | 2022.05.28 |
|---|---|
| 가상 쇼핑몰 고객 주문데이터 2. 고객 Retention 코호트 분석 (0) | 2022.05.28 |
| 가상 쇼핑몰 고객 주문데이터 1. 데이터 전처리 (0) | 2022.05.28 |
| 카페 상권 분석 (2) | 2022.05.26 |
| 부동산 데이터 전처리 (0) | 2022.01.11 |


